En EBICYS acostumbramos a trabajar con uno de los activos más importantes de las organizaciones: sus datos. Para que estos sean realmente de provecho deben estar en un formato que permita:
- Compartirlos
- Depurarlos
- Enriquecerlos
- Reutilizarlos
- Analizarlos
- Visualizarlos
En muchas ocasiones el formato no es el apropiado y solo cumple alguno de estos objetivos.
Como ejercicio hemos tomado los datos de los subsidios de reconstrucción adjudicados a los damnificados por el último gran terremoto que remeció a Chile el 27/02/2010. El Ministerio de Vivienda publicó en su sitio oficial el listado de los algo más de 100.000 subsidios en un archivo PDF de un tamaño de 75 MB lo que permite medianamente (muy grande y de lenta descarga) el primer objetivo, es decir compartirlos, pero este formato solo es de utilidad para quienes quieran auditar uno a uno el listado pero no permite cumplir ninguno de los demás objetivos ya mencionados perdiendo la oportunidad de sacar un mayor provecho a los mismos.
Comprendemos que el objetivo principal era el de comunicar la nómina de los beneficiados pero sería bueno que los sitios del estado comiencen a entregar "servicios de datos" , tal como lo hacen otros estados, para su utilización y análisis.
Haciendo el paralelo con lo que sucede en muchas organizaciones cuando nos enfrentamos a un proyecto de Datamarts/Datawarehouse el archivo PDF ejemplifica muy bien lo que sucede en la mayoría de los casos:
- los datos no están en el formato que esperábamos o eran de difícil acceso
- necesidad de conversión de datos
- no están normalizados (ej.: ciudades Chillán, Chillan, Viña del Mar, Viña Del Mar,etc)
- no cumplen todos con el mismo formato y hay "suciedad" en los mismos (falta de separadores/espacios)
solo por mencionar algunas cosas.
Todo el proceso de Profiling, Limpieza y normalización, Extracción, Transformación (enriqueciendo la información) es el que tomó la mayor cantidad de tiempo para que los datos fuesen de utilidad.
Como en todo proyecto de este tipo las etapas anteriores fueron las que consumieron el 80-90% del tiempo y las visualizaciones el restante 10%.
Finalmente cargamos los datos a nivel de detalle ya enriquecidos en Google Fusion Tables (para compartirlos de una forma más fácil y que permita su reutilización) hicimos la visualización para permitir el análisis de los mismos y formarnos una imágen macro de la situación. En definitiva convertirlos en información útil para su análisis.
Las herramientas que utilizamos son:
- FoxIt para convertir de PDF a texto
- Google Refine, Excel 2010 para profiling, normalización y limpieza
- Google Fusion Tables como almacén de datos y visualización
Los siguientes fueron los resultados.
ADVERTENCIA: ESTAS VISUALIZACIONES PODRIAN CONTENER ERRORES DEBIDO A QUE LOS DATOS NO FUERON AUDITADOS, EL POCO TIEMPO EN QUE SE LLEVO A CABO EL EJERCICIO Y PROBLEMAS AL CONVERTIRLOS. ESTO SE HACE COMO UN EJERCICIO PARA DEMOSTRAR LA UTILIDAD DE LAS VISUALIZACIONES Y DE COMPARTIR DATOS PUBLICOS EN LA RED. PARA CUALQUIER CONCLUSION RECOMENDAMOS VALIDAR LOS RESULTADOS CONTRA EL ARCHIVO EN FORMATO PDF PUBLICADO EN EL SITIO DEL MINISTERIO DE LA VIVIENDA.
La tabla con la totalidad de los datos puede ser navegada, consultada y descargada aquí
Los colores representan la concentración de subsidios siendo la escala : verde, amarillo, rojo y luego los íconos más grandes (mayor cantidad), amarillo y rojo. Al hacer "click" en el ícono se muestra el total de subsidios de la comuna.
viernes, 24 de diciembre de 2010
martes, 21 de diciembre de 2010
Ya está disponible la versión 3.2SR1 de Palo BI Suite !!
Este nuevo release trae una nueva demo : "Bikers Best Demo" que se instala automáticamente con el one step setup. Se pueden ver ejemplos de Framesets, Navegación y GEO Widget (con Google Maps y paso de parámetros, en acción. En las nuevas demos vienen ejemplos de las macros (PHP) y su uso. Descargar en http://ow.ly/3szEB
Adicionalmente pueden generarse "snapshots" XLSX y WSS directamente desde los reportes además de PDF.
martes, 23 de noviembre de 2010
Novedades en el Roadmap BI/DW de Microsoft
Microsoft anunció la semana pasada las novedades que traerá la nueva versión de SQL Server cuya liberación está planificada para fines del 2011.
El nuevo release tiene el nombre "Denali" y viene marcado principalmente por mejoras para el desarrollo de proyectos de Datawarehouse y Business Intelligence.
Motor Columnar
Ya es un hecho que muchos fabricantes de bases de datos están adoptando las tecnologías de base de datos columnares mejor diseñadas para aplicaciones analíticas orientadas más a la consulta que al manejo de transacciones.
Microsoft está haciendo lo suyo con Vertipaq el motor columnar in memory que ya es parte de PowerPivot, el nuevo ad-in de Excel 2010, que ya es capaz de manejar millones de transacciones. Actualmente esta tecnología está muy ligada al libro Excel, de hecho los datos se almacenan como parte de este último, y la única forma de compartirlo es mediante su publicación en Sharepoint. Esto último además le impone una limitande de 2GB al tamaño del archivo.
Aunque puede ser suficiente para compartir dashboards y algunos análisis no lo es para una plataforma más robusta de BI que soporte por ejemplo seguridad a nivel de elementos de sus dimensiones. Por ejemplo para separar los datos de dos áreas/grupos de usuarios para que unos no puedan ver los datos de los otros hay que construir 2 libros lo que obviamente es un problema.
Las buenas noticias son que Vertipaq o el nuevo motor columnar (nombre de proyecto "Apollo") pasará a ser parte del core de SSAS (analysis services) en donde sí habrá manejo de grandes volúmenes y seguridad.
Nuevo Modelo Semántico
Algo que también hacía falta es un modelo unificado para SSRS y SSAS (reporting services y análisis services). Este modelo unificado será el BISM el cual contendrá el modelo semántico (futuro) para SSRS y SSAS. Con esto habrá un solo modelo para reportes sobre fuentes relacionales (tablas) y multidimensionales no obligando a quienes solo deseen emitir reportes a general un modelo dimensional.
Lo anterior no significa que el UDM sea dejado de lado (al menos no por bastante tiempo más). Ambos modelos coexistirán. El BISM incorpora a DAX a Analysis Services, lenguaje de consulta y expresiones que hoy utiliza PowerPivot, lo que hará que los modelos puedan ser accedidos mediante un lenguaje más simple para los usuarios. DAX podrá consultar modelos dimensionales y relacionales así como tablas no relacionadas entre sí y permitirá construir consultas de forma más intuitiva.
Excel
Excel continuará siendo el cliente BI por excelencia y soportará tanto UDM como BISM.
Crescent
Es el nombre del proyecto de una nueva herramienta de reportes ad hoc y de visualización que promete ser más interactiva, visual y moderna.
Reporting Services
Adicionalmente a todas las mejoras en los gráficos gracias a la compra de tecnología de Dundas, debería consultar de forma nativa mediante MDX al BISM y probablemente también mediante DAX aunque habrá que esperar a que Microsoft aclare un poco más el roadmap.
Tal como podemos observar, el mercado de plataformas BI, será cada día más entretenido y competitivo.
El nuevo release tiene el nombre "Denali" y viene marcado principalmente por mejoras para el desarrollo de proyectos de Datawarehouse y Business Intelligence.
Motor Columnar
Ya es un hecho que muchos fabricantes de bases de datos están adoptando las tecnologías de base de datos columnares mejor diseñadas para aplicaciones analíticas orientadas más a la consulta que al manejo de transacciones.
Microsoft está haciendo lo suyo con Vertipaq el motor columnar in memory que ya es parte de PowerPivot, el nuevo ad-in de Excel 2010, que ya es capaz de manejar millones de transacciones. Actualmente esta tecnología está muy ligada al libro Excel, de hecho los datos se almacenan como parte de este último, y la única forma de compartirlo es mediante su publicación en Sharepoint. Esto último además le impone una limitande de 2GB al tamaño del archivo.
Aunque puede ser suficiente para compartir dashboards y algunos análisis no lo es para una plataforma más robusta de BI que soporte por ejemplo seguridad a nivel de elementos de sus dimensiones. Por ejemplo para separar los datos de dos áreas/grupos de usuarios para que unos no puedan ver los datos de los otros hay que construir 2 libros lo que obviamente es un problema.
Las buenas noticias son que Vertipaq o el nuevo motor columnar (nombre de proyecto "Apollo") pasará a ser parte del core de SSAS (analysis services) en donde sí habrá manejo de grandes volúmenes y seguridad.
Nuevo Modelo Semántico
Algo que también hacía falta es un modelo unificado para SSRS y SSAS (reporting services y análisis services). Este modelo unificado será el BISM el cual contendrá el modelo semántico (futuro) para SSRS y SSAS. Con esto habrá un solo modelo para reportes sobre fuentes relacionales (tablas) y multidimensionales no obligando a quienes solo deseen emitir reportes a general un modelo dimensional.
Lo anterior no significa que el UDM sea dejado de lado (al menos no por bastante tiempo más). Ambos modelos coexistirán. El BISM incorpora a DAX a Analysis Services, lenguaje de consulta y expresiones que hoy utiliza PowerPivot, lo que hará que los modelos puedan ser accedidos mediante un lenguaje más simple para los usuarios. DAX podrá consultar modelos dimensionales y relacionales así como tablas no relacionadas entre sí y permitirá construir consultas de forma más intuitiva.
Excel
Excel continuará siendo el cliente BI por excelencia y soportará tanto UDM como BISM.
Crescent
Es el nombre del proyecto de una nueva herramienta de reportes ad hoc y de visualización que promete ser más interactiva, visual y moderna.
Reporting Services
Adicionalmente a todas las mejoras en los gráficos gracias a la compra de tecnología de Dundas, debería consultar de forma nativa mediante MDX al BISM y probablemente también mediante DAX aunque habrá que esperar a que Microsoft aclare un poco más el roadmap.
Tal como podemos observar, el mercado de plataformas BI, será cada día más entretenido y competitivo.
miércoles, 27 de octubre de 2010
Palo BI Suite 3.2 Ad portas
En solo unos días más, el 31 de octubre de 2010, será liberada la versión 3.2 de Palo Bi Suite. Entre las características nuevas están:
- Publicación desde Excel de los reportes a la web y lectura desde Excel de los reportes publicados en el server
- Instalador unificado (instala plug-in Excel, server y web, etl)
- Mayor personalización de la interfaz web de las aplicaciones
- Incremento de la performance del motor olap
Adicionalmente junto con este release sería liberada la versión que hace uso de GPUs (procesadores gráficos de video) para acelerar las operaciones de cálculo. Esta versión especial de Palo Olap es el Palo Olap Accellerator. Esta es una de las características que personalmente más espero a tener disponible ya que abre un mundo de posiblidades para los planificadores.
El uso de GPUs permite que estaciones de trabajo y servidores de bajo costo utilicen la capacidad de multiproceso paralelo de estos procesadores especializados logrando un poder de procesamiento que no estaba al alcance (al menos a un bajo costo) para los usuarios de negocio.
Imaginen a un planificador en el departamento de RRHH de una empresa simular distintos escenarios de sueldos, compensación, bonos,etc para miles de trabajadores y tener la respuesta en segundos. En el caso del retail fijar metas diarias de venta no solo a nivel de categorías sino de SKUs, simular escenarios de cambio de precios, costos,etc. O prorratear costos de marketing o administrativos a nivel de producto en cada punto de venta.
Sin duda el 3.2 será un release que nos traerá bastantes novedades
- Publicación desde Excel de los reportes a la web y lectura desde Excel de los reportes publicados en el server
- Instalador unificado (instala plug-in Excel, server y web, etl)
- Mayor personalización de la interfaz web de las aplicaciones
- Incremento de la performance del motor olap
Adicionalmente junto con este release sería liberada la versión que hace uso de GPUs (procesadores gráficos de video) para acelerar las operaciones de cálculo. Esta versión especial de Palo Olap es el Palo Olap Accellerator. Esta es una de las características que personalmente más espero a tener disponible ya que abre un mundo de posiblidades para los planificadores.
El uso de GPUs permite que estaciones de trabajo y servidores de bajo costo utilicen la capacidad de multiproceso paralelo de estos procesadores especializados logrando un poder de procesamiento que no estaba al alcance (al menos a un bajo costo) para los usuarios de negocio.
Imaginen a un planificador en el departamento de RRHH de una empresa simular distintos escenarios de sueldos, compensación, bonos,etc para miles de trabajadores y tener la respuesta en segundos. En el caso del retail fijar metas diarias de venta no solo a nivel de categorías sino de SKUs, simular escenarios de cambio de precios, costos,etc. O prorratear costos de marketing o administrativos a nivel de producto en cada punto de venta.
Sin duda el 3.2 será un release que nos traerá bastantes novedades
lunes, 18 de octubre de 2010
Publicación de reportes desde Excel a Palo Web
Una de las nuevas funcionalidades que estarán disponibles en Palo BI Suite 3.2 es la publicación directa de reportes desde Excel a Web y su posterior recuperación y ejecución desde el server por parte de los usuarios que utilicen Excell como interfaz.
He aquí un video demostrando esta útil característica.
He aquí un video demostrando esta útil característica.
lunes, 2 de agosto de 2010
QlikView: una herramienta más del arsenal
Me parece interesante comentar y transcribir una discusión reciente en un blog de especialistas en QlikView. El tema era el por qué es necesario modelar y construir un Datawarehouse y no sólo construir toda la aplicación de apoyo a la toma de decisiones utilizando sólo la herramienta QlikView, tal como lo promueve el marketing de dicha compañía.
La verdad es que en la mayoría de las empresas no se encuentran las condiciones ideales para que los datos sean utilizados directamente por las aplicaciones analíticas. Es común apreciar problemas de calidad de datos, codificación y/o clasificación de productos o clientes que no concuerdan entre los distintos sistemas, necesidad de transformaciones de los datos, etc.
Para quienes deseen revisar la discusión original pueden verla en este enlace. A continuación menciono lo más relevante:
1.- La gente de marketing de QlikView al parecer siempre olvida que para lograr esa bella forma de visualización y análisis SE REQUIERE de un datawarehouse con diseño sólido y bien construido. Los datos, la mayoría de las veces, no se encuentran disponibles de la forma ideal que muestran las demos.
2.- Usted podrá construir aplicaciones bien integradas con QlikView pero cuando se trata de metadata, mantenimiento, integración desde múltiples fuentes, data lineage, manejo de la historia, se queda corto. Es una excelente herramienta pero debería ser utilizada como un front-end y no como un reemplazo al datawarehouse.
3.- Los datos deberían ser almacenados en un formato neutral respecto del vendedor y de una forma tan abierta como sea posible.
4.- Los datos deben estar disponibles para que sean trabajados por otras herramientas con funcionalidades que requieran los usuarios.
5.- QV replica el efecto Excel. Datos proliferenado en distintos recipientes
6.- Se generan múltiples fuentes de la verdad, algo que debe evitarse en una buena implementación. También terminan generándose Data Marts no integrados unos con otros favoreciendo las múltiples verdades.
7.- Deben considerarse las regulaciones extremas sobre privacidad en gobiernos que piden a gritos datamanagement y arquitecturas sofisticadas que acompañen sus datos y solución de BI.
8.- Carencias de control y administración de Metadata. Un pilar sobre el cual cualquier arquitectura de administración debe estar construida.
9.- En a realidad muchas y especialmente las grandes empresas NUNCA permiten el acceso directo a los sistemas transaccionales lo cual es correcto por lo que se hace necesario construir un datastore y refrescarlo de forma periódica. En la medida que aumenten los datos llegará a ser un reto a la arquitectura del repositorio.
Lo cierto es que QlikView, independientemente de lo innovador de su tecnología y de que no se trata tan solo de un visualizador sino que además posee un poderoso motor que correlaciona la información “in-memory”, es sólo un arma más del arsenal de herramientas que pueden utilizarse para sacar provecho a los datos contenidos en el datawarehouse corporativo.
Es interesante el hecho de que el mensaje de marketing haya sido tan atractivo para los usuarios finales y muchos gerentes de sistemas. El mensaje es no se complique diseñando y construyendo sus datamarts, datawarehouse ni cubos. No gaste tiempo valioso en estas actividades y dé poder a los usuarios finales y construya sus aplicaciones directamente conectadas a sus fuentes de datos. Obviamente aún existe una deuda con los usuarios finales tanto en facilidades de uso de las herramientas BI y capacidades de autoservicio que obtengan como resultado menores tiempos de implementación y mayor satisfacción.
No concuerdo con que sea más demoroso hacer un cubo que una bd in-memory para QlikView. Un ejemplo es Cognos PowerPlay desde sus antiguas versiones. Bastaba indicar los datos fuentes ya sea en archivos planos o tablas de una BD y el wizard de su módulo Transformer diseñaba las dimensiones, jerarquías y con otro click se cargaba el cubo y se visualizaba . ¡Cubos instantáneos más rápido que con QlikView y sin lenguajes propietarios de extracción!.
Los usuarios desean construir sus propios análisis y tener la facilidad de integrar sus datos externos. No desean esperar meses para que sus análisis estén disponibles. Estas aspiraciones las están tratando de satisfacer también empresas como Microsoft con PowerPivot y MS SQL Server 2008 R2 en donde se mezcla el autoservicio de los usuarios finales con la administración de los profesionales de TI.
Lamentablemente los sistemas de decisión no son solo cubos como los de Cognos PowerPlay o bases de datos in-memory como la de QlikView. Necesitamos datos limpios, estandarizados, accesibles en formatos abiertos por las distintas herramientas de software. Necesitamos además la “fuente única de la verdad” la cual no puede estar toda contenida en un solo cubo de PowerPlay o una base de datos de QlikView.
viernes, 2 de julio de 2010
Nueva Demo de Palo Web
Para quienes estén interesados en ver cómo se vé Palo en la web he aquí el enlace:
Ir a Palo Web Demo
Que lo disfruten!
Ir a Palo Web Demo
Que lo disfruten!
miércoles, 30 de junio de 2010
Pivot Tables y Palo Olap

Para quienes gusten de trabajar con las tablas pivote de Excel hay una muy buena noticia. Con el Palo ODBO provider es posible conectarse a los cubos de Palo desde Excel 2003, 2007 o 2010. Lo anterior es relevante sobre todo para usuarios que ya estaban acostumbrados a trabajar con esta útil herramienta de Excel.
Antes de poder acceder un cubo con el ODBO provider, debemos indicar en el Modeller cuáles serán las dimensiones de Tiempo y la que contendrá las métricas ya que en un cubo estándar de Palo estas no requieren de una diferenciación especial.

Las reglas que deberemos respetar son:
1.- En cada cubo que se desee acceder debe existir una dimension llamada "Measures"
2.- Cada dimensión deberá tener solo 1 elemento de nivel superior. El equivalente a "All".
3.- Las jerarquías paralelas de Palo no serán permitidas. Para cada elemento un único padre es permitido.
Un detalle importante al trabajar con MDX es el cambio de la estructura de la dimensión de Tiempo. En un cubo tradicional de Palo comúnmente usamos
una dimension que contiene los elementos de los años, por ej.: 2009,2010,2011 y otra que contiene los meses de Enero a Diciembre, así el cruce de ambas nos proporciona el contexto de tiempo que estamos visualizando.
Para ajustarse a MDX ,y trabajar correctamente, el ODBO provider de Palo requiere que la dimensión de tiempo contenga todos los elementos de tiempo. La dimensión quedaría de la siguiente forma: 2009_H1_Q1_M12_W4_D1 donde
H: será mitad del año
Q: será trimestre
M: será mes
W: será semana
D: será el día
o
Año hasta Mes Año hasta Día

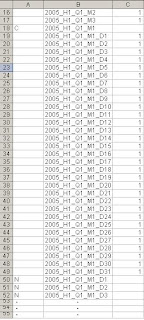
Si bien es cierto que Palo no requiere de este tipo de dimensiones, es necesario que la ocupemos si vamos a acceder nuestro cubo con MDX. Los prefijos pueden ser distintos pero lo importante es que nos den información sobre en qué nivel estamos posicionados.
Los niveles son opcionales siendo válido por ejemplo tener 2009_D1 (año-día) o la estructura completa.
sábado, 3 de abril de 2010
Finalmente Palo BI Suite 3.1 GA está disponible

El pasado 31 de marzo Jedox anunció la disponibilidad general de la versión 3.1 de Palo BI Suite. La imagen antes de este texto no es Excel 2007 es la interfaz web de desarrollo del producto.
La nueva versión community es considerablemente más veloz que el pre-release o Ramp-Up version. Se nota que el equipo de desarrollo de Jedox trabajó intensamente para solucionar problemas de rendimiento que tenía la ramp-up version y algunos bugs. Se incluyen además dashboards, reportes e ingreso de datos como demo.
La nueva instalación no requiere desinstalar previamente. El instalador se encarga de detectar la versión anterior, conservar los desarrollos e instalar el nuevo software.
Les puedo comentar que las mejoras en velocidad de la versión web son notorias.
Tal como Jedox lo había anunciado previemente esta nueva versión elimina el Report Manager y Olap manager de la interfaz web. Estos dos componentes solo estarán disponible en le versión comercial.
El enlace para descargar la nueva versión aquí
martes, 23 de marzo de 2010
Google Fusion Table, ¿nueva suite de BI?
Hace algunos días probé Google Fusion Tables uno de los productos de Google Labs. La verdad es que este gigante de la tecnología está abarcando rápidamente muchos ámbitos y como una de las principales utilidades para los usuarios de Google es la recuperación de información un próximo paso es el análisis de la misma.
Aunque se encuentra en estado embrionario ya puede visualizarse una nueva aplicación de Business Intelligence la cual haga uso de bigtable, mapreduce y feeds hacia los repositorios de información.
Los análisis son de datos de los sismos ocurridos en Chile entre el 11 y el 16 de Marzo de 2010. Son pocos datos pero la idea es mostrar algo de la funcionalidad.
A continuación algunas visualizaciones:
Geolocalización automática
Scatter graphics
Gráficos de línea
Movimiento
Es uno de los más llamativos pero lamentablemente no lo pude incluir aquí. El link de la vista es http://tables.googlelabs.com/DataSource?snapid=33110 . Pueden cambiar la Opcion "Colores exclusivos" y "Tamaño" así como seleccionar los distintos "tabs".
Para quienes estén interesados el link es http://tables.googlelabs.com/DataSource?dsrcid=146304 . Prueban las distintas opciones en la opcion de menú "Visualize"
Las Fusion Tables proveen de facilidades para hacer merge con otras tablas, filtrar y funciones de agregación.
Habrá que seguirlas de cerca.
domingo, 31 de enero de 2010
Palo y SAP BW & R3
En su último release, Palo incluye el conector para SAP R/3 (ya incluía el de BW) por lo que se transforma en una muy buena alternativa para el desarrollo de un sistema de Planificación o análisis OLAP, fácil y rápido de implementar, para aquellos usuarios que no necesitan de la funcionalidad completa de BW o no quieren esperar (o invertir) en su implementación.
Los datos se extraen a nivel de tabla de manera simple y efectiva o a través de una interfaz RFC/BAPI genérica . El proceso ETL es modelado utilizando la interfaz web de Palo ETL inclído en Palo BI Suite.
A continuación un diagrama que muestra qué componentes están disponibles en las distintas versiones:
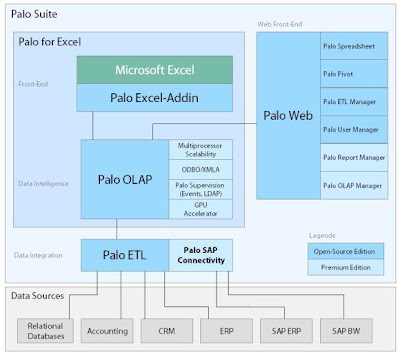
Pueden ver el post original en http://www.paloinsider.com/ y más información sobre el producto en http://www.jedox.com/en/products/palo-sap-connectivity.html
martes, 26 de enero de 2010
Nuevo Esquema de Licenciamiento de Palo BI Suite
La semana pasada Jedox ha cambiado el esquema de licenciamiento de su producto Palo BI Suite. A contar de ahora se adopta el esquema de suscripción anual (incluye producto mas soporte) y se cambia desde usuario concurrente a usuario nominado. Esto último permitirá reducción en los costos de entrada de proyectos con menos usuarios.
Adicionalmente a la reducción en los precios debido al cambio de esquema se ha creado la alternativa de Supported Open Source (SOS), esto es, para empresas que no desean adquirir la versión Premium (anteriormente comercial) pero desean tener garantía sobre el producto y alternativa de consultas a soporte técnico. La SOS no tiene límite de usuarios a diferencia de la Premium que sí se licencia por rango de usuarios nominados. La alternativa de SOS está ahora disponible también para el popular Palo for Excel.
Para clientes actuales que deseen adquirir licencias bajo el esquema de usuarios concurrentes, esto será posible hasta el 15 de febrero de 2010. De todas maneras dependiendo la instalación hay suficientes alternativas para evaluar la más conveniente en cada caso.
A continuación la matriz con las diferencias entre las distintas distribuciones:

Suscribirse a:
Entradas (Atom)